こんにちは。レッジのデータサイエンティストの松本です。
レッジでは、クライアント先に常駐してデータ・ドリブンな課題解決に取り組んだり、ダイナミックプライシングやNLP周りのアルゴリズムを受託開発したり、クライアント先へのBI導入の推進など、幅広くデータ利活用に関わる業務に取り組んでいます。
さて、今回はSDV(Synthetic Data Vault)による合成データで学習した機械学習モデルの有効性を検証します。
後述するように、個人情報を匿名化する手法であるk-匿名化や差分プライバシー基準の担保は実データの構造や特性を歪めます。 したがって、これらの匿名化技術を用いてデータサイエンス系のコンペ等でデータを提供してモデル構築の知見を得られたとしても、そのモデルを実データに適用すると精度が悪化してしまう可能性があります。
このようなデータ匿名化の課題を克服する手法がデータの合成です。 合成したデータで学習した機械学習モデルが実データで学習したモデルと同等の精度を担保できるのであれば、今以上に企業や政府機関でのデータ活用の敷居が低くなる でしょう。
本稿ではまず合成データについて説明した後に、合成データを生成できるSDVライブラリについて説明します。そして、最後に合成データで学習した機械学習モデルの有効性を検証します。
合成データとは
以下の要件を満たしたデータを合成データと呼びます。
- 元のデータと統計的にある程度似ていること
ex)平均、分散といった要約統計量が元のデータと似ている - 元のデータと形式的、構造的に似ていること
ex)テーブルの主キー、外部キーが元データと似ている
この2つの要件を満たす合成データを生成するためには、元のデータと同一の形式や構造を保持したうえで統計モデルを構築する必要があります。
後述するSDVは、元のデータをモデリングし、そのモデルから合成データを生成(サンプリング)できるライブラリです。
なぜ合成データが必要か
企業がデータを収集・共有・活用する場合、データを保護したりプライバシーを遵守するためにk-匿名化や 差分プライバシー基準の担保など、データを何らかの方法で匿名化する必要があります。
しかし、上記のデータの匿名化は本来のデータの構造や特性を歪めるため、匿名化したデータで学習した機械学習モデルを実データに適用すると悪影響を及ぼす可能性があります。
このような データの匿名化に関する課題を克服する手法がデータの合成です。
データを合成することによって、そのままでは公開できないようなデータセットでも個人情報を明らかにすることなく、データセットの属性間の特性や関係を維持できます。 合成したデータには個人の情報が含まれていないため、共有も容易になります。
また、理論的には、合成したデータで機械学習モデルを学習させても、最終的には実データで学習させたモデルと同等の精度を得ることが可能です。*1
SDVとは
Synthetic Data Vault (SDV) は、単一のテーブルデータ*2やリレーションを有する複数のテーブルデータ*3、時系列データセットを学習し、元のデータセットと同一のデータ型・統計的特性を持つデータを合成できるライブラリです。
今回は単一のテーブルデータとして、分類タスクの入門でお馴染みのirisデータセットを利用します。 SDVではテーブルデータをGaussianCopura Model(正規コピュラモデル)*4に基づいてモデリングし、データを合成していきます。 SDVで利用できるモデルはGaussianCopura Modelの他にも、CTGAN ModelやCopulaGAN Modelがあります。
また、時系列データ、リレーションを有する複数テーブルのデータセットに対するSDVライブラリの使用方法については公式のチュートリアルやこちらで説明されているので、興味があればご参照ください。
合成データで学習した機械学習モデルの有効性を検証する方法
SDVにより合成したデータで学習したモデルと、実データで学習したモデルの精度を比較します。 データ分割での意図せぬ特徴量やターゲット変数の偏りを防ぐするため、以下のK分割交差検証を行います。
- データセット全体を5分割し、1/5をテストデータ、4/5を学習データとする
- 4/5の学習データでSDVモデル(GaussianCopura Model)を学習させ、学習データと同数のデータを合成する
- 合成データでロジスティック回帰モデルを学習させる
- 学習データでロジスティック回帰モデルを学習させる
- テストデータに対しての2モデルの精度を評価する
上記ステップにおける2~5を5分割繰り返し、平均値を算出します。

また、合成データにおけるモデル改善と実データにおけるモデル改善の対応を確かめるため、ロジスティック回帰モデルの正則化パラメータを複数設定します。
検証
今回はローカルのDockerコンテナ上で検証しました。 以下で紹介するコードはGitHubで確認できます。
まず、次のコマンドでsdvライブラリをインストールします。
!pip install sdv
sdvライブラリをインストール後、いったん、データセット全体をSDVで学習して合成したデータと、元のデータの分布を比較してみます。 なお、検証ではscikit-learnのirisデータセットを使用します。 以下はデータセット全体をSDVで学習し、学習データと同数のデータを合成するコードです。
from sdv.tabular import GaussianCopula from sklearn.datasets import load_iris # 変数定義 field_transformers = { 'sepal length (cm)': 'float', 'sepal width (cm)': 'float', 'petal length (cm)': 'float', 'petal width (cm)': 'float', 'target': 'categorical' } gc = GaussianCopula(field_transformers=field_transformers) # irisデータセットをロード iris = load_iris() # 特徴量 data = iris.get('data') # ターゲット変数 target = iris.get('target') # 特徴量とターゲット変数をまとめてDataFrameに変換 data_tmp = pd.concat([pd.DataFrame(data, columns=iris.get('feature_names')), pd.DataFrame(target, columns=['target'])], axis=1) # GaussianCopulaでモデリング gc.fit(data_tmp) # 合成するデータ数 N = len(data_tmp) # GaussianCopulaからデータを合成 sampled = gc.sample(N)
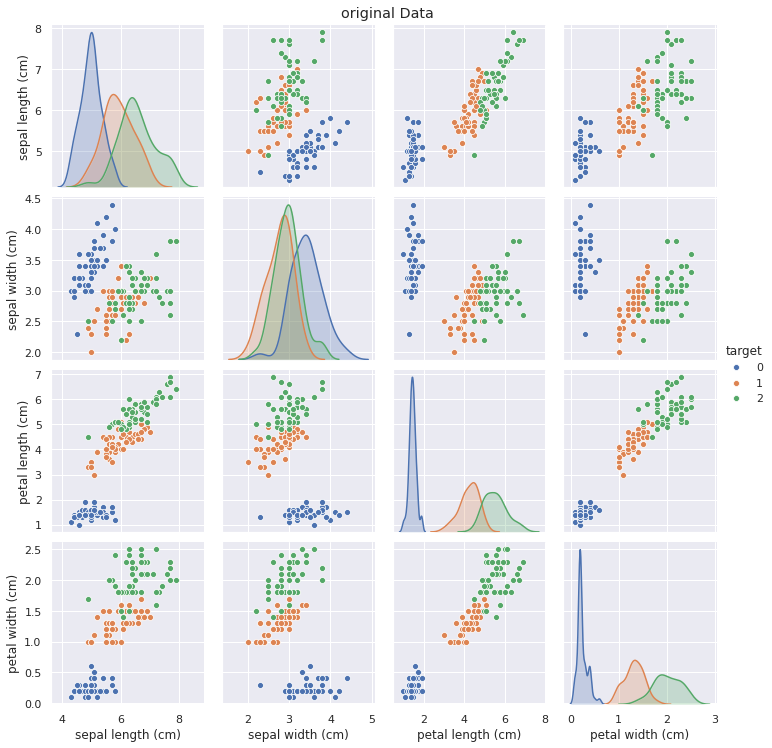
元のデータのペアプロットを確認します。
# 元のデータのペアプロット g = sns.pairplot(data=data_tmp, hue='target') g.fig.suptitle('original Data', y=1.02)
次に、合成データのペアプロットを確認します。
# 合成データのペアプロット g = sns.pairplot(data=sampled, hue='target') g.fig.suptitle('generated Data by SVD', y=1.02)
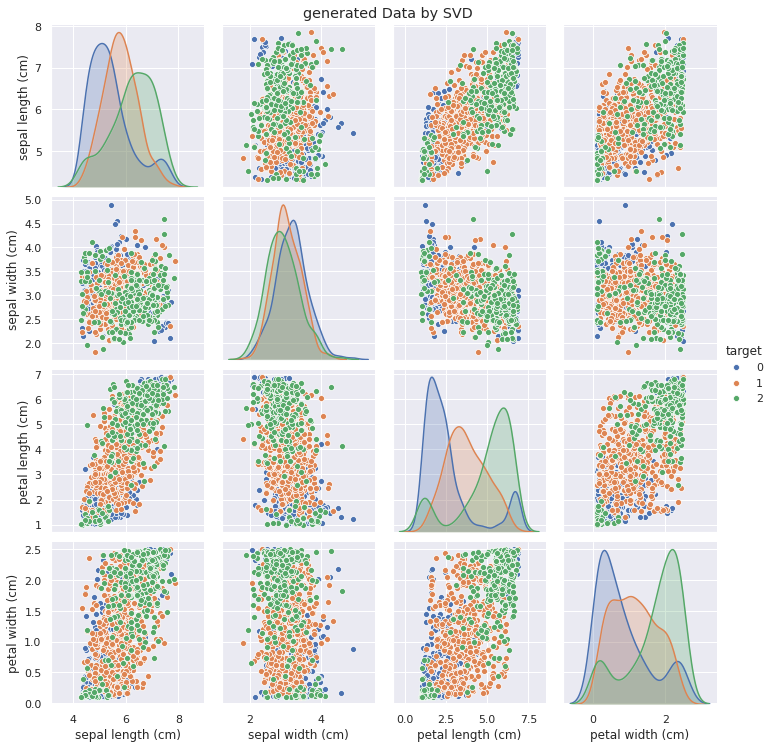
元のデータと比較して、合成データでは特に2変数間の分布についてターゲット変数が綺麗に分離していないように見えますが、これはSVDによるデータ生成過程に起因しています。
SVDでは、元のデータにおける各特徴量の分布パラメータ*5と特徴量間の共分散をもとにデータをサンプリングします。
そのため、少量ではあるものの確率分布の裾野に存在するデータも生成されるため、元のデータほどターゲット変数が綺麗に分離しません。*6
ただし、ターゲット変数間の各特徴量の大小関係は合成データにおいても元データとほぼ同じであることがわかります。
次に、「合成データで学習した機械学習モデルの有効性を検証する方法」で記載した交差検証を実施します。
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import StratifiedKFold # 層化5分割 skf = StratifiedKFold(n_splits=5, shuffle=True) syn_scores = list() origin_scores = list() # ロジスティック回帰のパラメータグリッド C = [1e-4, 1e-3, 1e-2, 1e-1, 1] for train_idx, val_idx in skf.split(data, target): # 学習データ X_train, X_test = data[train_idx], data[val_idx] # テストデータ y_train, y_test = target[train_idx], target[val_idx] # 学習データの特徴量とターゲット変数を結合 train_tmp = pd.concat([pd.DataFrame(X_train, columns=iris.get('feature_names')), pd.DataFrame(y_train, columns=['target'])], axis=1) # GaussianCopulaでモデリング gc.fit(train_tmp) # 学習データと同数をサンプリング sample_gc = gc.sample(len(train_tmp)) syn_score = list() ori_score = list() for c in C: # 合成データに対するロジスティック回帰モデルを学習させる lr_syn = LogisticRegression(C=c) lr_syn.fit(sample_gc[iris.get('feature_names')], sample_gc['target']) # 元のデータに対するロジスティック回帰モデルを学習させる lr_ori = LogisticRegression(C=c) lr_ori.fit(X_train, y_train) syn_score.append(lr_syn.score(X_test, y_test)) ori_score.append(lr_ori.score(X_test, y_test)) syn_scores.append(syn_score) origin_scores.append(ori_score)
交差検証で算出した、各正則化パラメータにおける精度の平均値を比較します。
import matplotlib.pyplot as plt import seaborn as sns import numpy as np sns.set() fig = plt.figure() ax = fig.add_subplot(1, 1, 1) ax.plot([str(i) for i in C], np.mean(np.array(syn_scores), axis=0), label='svd') ax.plot([str(i) for i in C], np.mean(np.array(origin_scores), axis=0), label='original') ax.legend() plt.show()

オレンジ色は元の学習データで学習したモデル、青色はSDVで合成したデータで学習したモデルです。 どちらのモデルでも、正則化パラメータが増加すれば精度の向上しているため、この正則化パラメータのグリッドにおいては精度と比例関係にあります。
これは、 合成データ上での最適なパラメータが実データにおける最適なパラメータに対応する ことを意味しています。 テストデータに対する精度はSDVで合成したデータで学習したモデルの方が低いですが、ハイパーパラメータの選定においては合成データを利用しても問題がないことがわかりました。
最後に
今回はサンプルデータ(iris)をもとに各特徴量やターゲット変数のデータを合成しましたが、SDVではカテゴリ変数を匿名化してデータを合成することも可能です。
今後このようなデータ合成に関する研究が発展し、データ合成のモデリング精度が向上していくことで、もっと機械学習の活用がオープンになっていくはずです。
昨今、事業会社でデータサイエンティストやデータエンジニアを雇って内製化しようする動きをちらほら聞きますが、データの匿名化が容易にできれば外部の知見を取り入れるチャンスが広がります。
今後は企業のデータもそうですが、政府機関のデータセットも活発に公開されて、どんどんオープンになっていけばいいなと思います。