こんにちは。レッジでデータサイエンティストをしている今村です。
今回は社内における業務効率化の取り組みの1つとして、音声文字起こしツールの開発秘話について紹介します。
音声文字起こしツールを活用することで、6時間程度かかっていた文字起こし作業が30分程度まで(90%以上)短縮することができました。AIを活用した業務改善のケースとして、開発背景からアプリケーションの構築、実際の作業に適用させた結果などを説明していきます。
記事の概要
本記事では下記のような流れで紹介していきます。
そもそもなぜ音声による文字起こしが必要だったのか?
使用したサービス
アプリケーション開発
周りの評価はどうだったのか
そもそもなぜ音声による文字起こしが必要だったのか?
なぜ音声による文字起こしが必要だったのかといいますと、取材やインタビューの文字起こしが非常に大変だったからです。
いきなり取材やインタビューというキーワードが出てきましたが、
実は弊社は国内最大級のPV数を誇るAI特化型メディア Ledge.ai を運営している会社です。

Ledge.aiでは国内外のAIに関する様々な記事が掲載しており、最新技術の紹介やトレンドを捉えた記事など日々更新しています。
記事を執筆する上で欠かせないのが取材やインタビューです。執筆のために取材時の音声を聞きながら、どういった会話をしていたのかを文字で起こし、その情報を元に記事を執筆していきます。
実はこの文字起こし、想像以上に非常に時間がかかります。音声を聞きながら、文字を書いていくので録音時間が長いほど時間がかかってしまいます。1時間の取材音声の場合、文字起こしに5~6時間かかってしまうこともあるそうです。
一方で、AIを始めとする最先端技術を扱うメディアとして情報の鮮度は非常に重要です。日々技術がアップデートされる業界であるため、取材した内容はできるだけ早く展開していくことが世の中的にも望まれていることと思います。 そのため、取材した情報をいかに早く公開できるかどうかが勝負となってきます。
つまり、取材した内容をできるだけ早く世の中に展開していく必要がある。でも、文字起こしが作業のボトルネックになってしまっているという現状があります。
そこで、
「音声ファイルから自動で文字起こし」できればいいのに
というニーズが生まれました。
もちろん、このニーズは別に新しいものでもなく、世の中には文字起こしに関するサービスが多数存在します。しかし、比較的高価なものであったり、従量課金体系のパターンが多く、気軽に手を出すことができない。
「それだったら自分たちで作ってしまおう」
と思い立ち、開発が始まりました。
使用したサービス
今回のアプリケーションでは下記のサービスを使用しました。
- 音声認識
- Azure Cognitive Service - Speech API - Speech to Text
- Webアプリケーションフレームワーク
- Streamlit
- 通知
- Slack Bot
音声認識
自動文字起こしのコア技術となる音声認識には、Microsoft社が提供するクラウドサービスAzureにあるAzure Cognitive Serviceを使用しました。
Azure Cognitive Serviceとは、クラウドベースで展開されるAI技術のAPIサービス群の総称であり、以下の5つのカテゴリで構成されています。
- Azure Cognitive Serviceが展開するカテゴリ群
- 視覚
- 音声
- 言語
- 意思決定
- 検索
Azure Cognitive Serviceの概要については こちら を参照してください。
今回は音声のカテゴリに該当するSpeech APIのSpeech to Textを用いて開発を行いました。Speech APIでは音声に関わる様々なAPIが用意されており、機能別に下記のような項目があります。
- Speech to Text
- 音声をテキストに書き起こす
- Text to Speech
- テキストを音声に変換する
- Speech Translation
- リアルタイム音声翻訳
- Speaker Recognition
- 音声に基づく話者識別
Webアプリケーションフレームワーク
アプリケーションの構築にはPythonのライブラリであるStreamlitを使用しました。
着想から素早く形にしたかったので、
以上の特徴を持つStreamlitを採用しています。
Streamlitについては、弊ブログの過去記事 、もしくは 公式ドキュメント を是非チェックしてみてください。
通知
APIを使ったとしても、文字起こしには時間がかかってしまいます。それまで画面を開いたまま辛抱強く待つのは本末転倒です。
本アプリケーションではSlackと連携を行い、文字起こしが完了したタイミングでSlackに通知する仕組みを構築しました。
特定の人をメンションしたり、文字起こししたファイルをSlackの特定のチャンネルにアップロードできます。
アプリケーション開発
さて、ここからは開発背景について紹介していきます。
早速ですが、記事執筆時点のWebアプリはこちらになります!

非常にシンプルですね。別にいいんです。あくまで社内の業務効率化が目的ですから。
本アプリケーションの構成は以下の通りです。
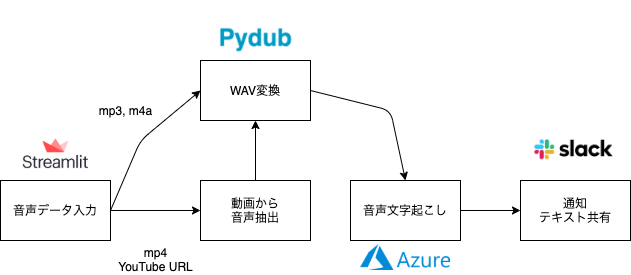
処理の流れは下記の通りです。
- 音声データ入力
- Steamlit上のファイルアップローダーから音声データをインプット
- WAV変換
- 音声ファイルの場合は、APIが読み込める
.wavに変換
- 音声ファイルの場合は、APIが読み込める
- 動画から音声抽出
- 動画ファイルの場合は、動画から音声を抽出した上で
.wavに変換
- 動画ファイルの場合は、動画から音声を抽出した上で
- 音声文字起こし
.wavをSpeech to Text APIに読み込み、音声から起こしたテキストを取得
- 通知・テキスト共有
- APIから得られたテキストをSlackに自動で投稿する
下記より順に詳細を説明していきます。
音声データ入力
データ入力はStreamlitのfile_uploader()メソッドを使用しています。
file_uploader()を使用することで1行でアップロード機能を付与できます。 なお、読み込んだファイルはBytesIO形式となります。
詳しくは file_uploader() - 公式ドキュメント を参照してください。
import streamlit as st uploaded_file = st.file_uploader('こちらからファイルを読み込み') print(type(uploaded_file)) # BytesIO
WAV変換
AzureのSpeech to Text APIにおいて、オーディオファイルの規定形式は.wavです。
そのため、音声認識を実行する前処理としてWAV変換を行います。
WAVの変換は pydub というライブラリを使用することで簡単に実現できます。
以下のコマンドでインストールできます。
pip install pydub
例えば、.mp3を.wavに変換するサンプルコードは下記の通りです。
from pydub import AudioSegment audio_file = 'YOUR_SONG.mp3' output_path = 'YOUR_SONG.wav' audio = AudioSegment.from_mp3(audio_file) audio.export(output_path, format='wav')
今回のアプリケーションでは、Streamlitのfile_uploader()によって音声ファイルはBytesIO形式で読み込まれます。
BytesIO形式のファイルはAudioSegment.from_file()にて読み取ることができます。
まとめると、全体を通して下記のように実装できます。
from pydub import AudioSegment import streamlit as st byte_file = st.file_uploader('こちらからファイルを読み込み') audio = AudioSegment.from_file(byte_file) audio.export(output_path, format='wav')
動画から音声抽出
動画ファイル(.mp4)
動画やYouTubeから文字起こしがしたい!という要望がありましたので、動画から音声を抽出してみました。
実は、.mp4のような動画ファイルについては、BytesIO形式に変換することで、上のWAV変換の処理がそのまま使えます。
そのため、動画に対しては上に記載したコードで対応ができてしまうので、特別な処理は不要です。
YouTube
YouTube動画については youtube-dl というライブラリを用いています。
このライブラリを使用することでYouTubeのURLから動画をダウンロードできます。
なお、このライブラリを使用する場合は、事前に ffmpeg をインストールする必要があります。
以下のコマンドでインストールできます。
pip install youtube-dl
今回は音声のみの抽出が必要なので、YouTubeのURLから該当の動画の音声を抽出していきます。
import youtube_dl from pydub import AudioSegment ydl_opts = { 'format': 'bestaudio/best', 'outtmpl': output_file_path + '.%(ext)s', # 出力先パス 'postprocessors': [ {'key': 'FFmpegExtractAudio', 'preferredcodec': 'mp3', # 出力ファイル形式 'preferredquality': '192'}, # 出力ファイルの品質 {'key': 'FFmpegMetadata'}, ], } url = "<YouTube URL>" ydl = youtube_dl.YoutubeDL(ydl_opts) # 指定したパスに音声ファイルが格納される _ = ydl.extract_info(url, download=True) # 格納された音声ファイルをpydubで読み込む audio = AudioSegment.from_mp3(output_file_path + '.mp3')
読み込んだ音声ファイルは上述したWAV変換の処理を行います。
音声文字起こし
いよいよAPIを使用した音声から文字起こしを行う部分の実装になります。
まず初めにAPIを使用するためのSpeech SDKをインストールします。
下記のコマンドを実行してインストールしておきます。
pip install azure-cognitiveservices-speech
文字起こしアプリケーションの実装コードは下記の通りです。
import time import azure.cognitiveservices.speech as speechsdk def recognize_audio(output, speech_key, service_region, filename, recognize_time=100): """ wav形式のデータから文字を起こす関数 --------------------------- Parameters output: str 音声から起こしたテキスト(再帰的に取得する) speech_key: str Azure Speech SDKのキー service_region: str Azure Speech SDKのリージョン名 filename: str 音声ファイルのパス recognize_time: int 音声認識にかける時間(秒) """ # Speech to Text 設定周り speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region) # 認識器の設定 audio_input = speechsdk.AudioConfig(filename=filename) speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_input) def recognized(evt): nonlocal output output += evt.result.text # 音声認識の実行 # recognize_timeの時間、継続して文字起こしを行う speech_recognizer.recognized.connect(recognized) speech_recognizer.start_continuous_recognition() time.sleep(recognize_time) return output filename = "<WAV File Path>" speech_key = "<Azure Speech SDK Subscription Key>" service_region = "<Azure Speech SDK Region Name>" output = "" output = recognize_audio(output, speech_key, service_region, filename, recognize_time=100)
この辺りはAzureのSpeech SDKの書き方に合わせて書いていきます。
具体的な内容は 公式ドキュメント を参照してください。
今回の記事では上で紹介した実装コードについて解説します。
まずは、Speech SDKを使用してAPIを使うために音声構成SpeechConfigを作成します。
# 音声構成の作成 speech_config = speechsdk.SpeechConfig( subscription="<paste-your-subscription-key>", region="<paste-your-region>")
続いて、音声ファイルの入力と音声認識器を作成します。
音声ファイルは.wav形式の音声ファイルパスを指定します。
# 音声ファイルの入力 filename = "<WAV File Path>" audio_input = speechsdk.AudioConfig(filename=filename) # 音声認識器の作成 speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_input)
最後に指定した秒数で継続的に音声認識を行います。
def recognized(evt): """ APIで文字起こしされたテキストを更新する関数 関数のスコープ外にある変数"output"に文字起こしされたテキストを更新する """ # nonlocalを使用することで関数のスコープ外である"output"を更新できるように宣言 nonlocal output # evt.result.textに文字起こしされたテキストが存在する # 変数outputにテキストを追記していく output += evt.result.text # 音声認識の実行 speech_recognizer.recognized.connect(recognized) # 音声認識の開始 speech_recognizer.start_continuous_recognition() # 指定した秒数待機する time.sleep(recognize_time)
継続的な音声認識を行うためには、音声認識の状態を管理しておく必要があります。
今回は関数recognized(evt)を定義し、文字起こしされたテキストをrecognize_timeで指定した秒数の間実行しています。
より詳細な内容については、継続的認識に関する 公式ドキュメント を参照してください。
以上が音声文字起こしアプリケーションの根幹となる音声認識の処理となります。
最終的なアウトプットは変数outputに格納されます。
通知・テキスト共有
取得したテキストは文字起こしをしたタイミングでSlackに自動投稿する仕組みを構築しました。
弊社インターンの大熊による協力で実現できました。
import time import slackweb from slack import WebClient def slack_send_notification(webhook_url, message): """ 文字おこしの完了をslackに通知する関数 --------------------------- Parameters webhook_url: str Slack環境変数(webhook_url) message: str Slackに送りたいメッセージ """ slack = slackweb.Slack(url=webhook_url) slack.notify(text=message) def slack_send_content(OAuth_Token, channel_id, file_name): """ 文字おこしの内容をスレッドに返信する関数 --------------------------- Parameters OAuth_Token: str Slack環境変数(OAuth_Token) channel_id: int Slack環境変数(Channel_id) file_name: str Slackに送信するファイルパス """ # clientの認証 client = WebClient(token=OAuth_Token) # チャンネルの履歴を取得 result = client.conversations_history(channel=channel_id) # 最新のメッセージのタイムスタンプを取得 ts = result["messages"][0].get('ts') client.files_upload( channels=channel_id, thread_ts=str(ts), initial_comment="議事録だよ", file=file_name, reply_broadcast = False ) # 文字起こしされたテキストをoutput.txtとして保存 with open('output.txt', 'w') as f: f.write(output) # 環境変数 slack_mention_id = "<mention_id>" slack_webhook_url = "<webhook url>" slack_channel_id = "<channel id>" slack_OAuth_Token = "<OAuth Token>" # Slackでの通知と文字起こしのテキストファイルの送信 message = "<@" + str(slack_mention_id) + "> 文字おこし完了したよ" slack_send_notification(webhook_url=slack_webhook_url, message=message) time.sleep(2) slack_send_content(OAuth_Token=slack_OAuth_Token, channel_id=slack_channel_id, file_name="output.txt")
SlackAPIを用いて文字起こししたテキストファイルをアップロードします。
メンション先を指定する<mention_id>は、Streamlitのインターフェイス上でユーザーが選択した項目に応じて自動で取得するようにしています。
import streamlit as st from slack import WebClient def slack_get_users(OAuth_Token): """ OAuth_Tokenの情報からユーザーIDとユーザー名を取得する関数 --------------------------- Parameters OAuth_Token: str Slack環境変数(OAuth_Token) """ user_ids = ['None'] user_names = ['None'] client = WebClient(token=OAuth_Token) result = client.users_list() for member in result["members"]: member_id = member.get('id') member_name = member['profile'].get('display_name') user_ids.append(member_id) user_names.append(member_name) user_ids_dic = dict(zip(user_names,user_ids)) user_names = sorted([name for name in user_names if name!='' and name!='None'], key=str.lower) user_names.insert(0, 'None') return user_ids_dic, tuple(user_names) slack_OAuth_Token = "<OAuth Token>" # OAuth TokenからSlackのユーザー名とIDを取得 user_ids_dic, user_names = slack_get_users(OAuth_Token=slack_OAuth_Token) # Streamlitによるプルダウン選択メニューを設定 user_name = st.selectbox( '議事録完成時にメンションするメンバーを選択', user_names) # メンション対象のユーザーIDを取得 slack_mention_id = user_ids_dic[user_name]
周りの評価はどうだったのか
当たり前の話ですが、業務改善ツールは現場が使ってくれないと意味がありません。
せっかく業務改善ツールを作ったとしても、使いにくかったり思ったような形ではないと「作って終わり」になってしまい、使用者開発者どちらもマイナスとなってしまいます。
そこで実際に使ってくれているLedge.ai編集部の方に評価してもらいました!
『Ledge.ai編集部に来てから、AIを導入している企業や著名人などに、インタビュー取材をする機会が多くなりました。 文字起こしに消耗される日々、つらい……。と思っていたときに、今村さんが文字起こしアプリのプロジェクトを手がけていることを知りました。
同アプリを使っていくなかで、
「ほど良い箇所で自動で改行してくれるシステムがほしい!」
「動画データからも(自動で音声を抽出して)文字起こしがしたい!」
「いっそのこと、YouTubeのURLを入力するだけで、文字起こしできるようにしたい!」
など、フィードバックをしたら、そのたびにすぐに要望どおりにアップデートしてくれました。 自分で文字起こししていたときとは"執筆"といった感覚でしたが、現在では同アプリが文字起こししてくれた文章を"編集"するだけになり、とんでもない業務効率化ができたと感じています。 今となっては、文字起こしアプリなしの取材記事の執筆は考えられません!!』
『文字を起こしただけでは褒められない世の中だからこそ、求められるアプリでした。 文字起こしを自動化しているとほかの会社の人に話すと、「レッジさんすげー!」「超うらやましい!」と言われます。鼻が高いです。
実際、メディアに携わる人以外でも、文字起こし作業が苦痛だと認識している人はこの世に多く存在しています。 それこそ、いろんな会社で文字起こしが必要な局面を強いられると思うのですが、強いられた方は死ぬほど苦痛だと思うんです。 何よりも時間がかかる……。1時間の音声データを文字起こしすると、5,6時間は最低でも必要になります。 でも、5,6時間かけて文字起こしをしたからって褒められるわけではないんです。
文字起こしは、文字を起こしをしたうえで、何かを作ったり、考えたりするための準備作業ですよね。 この準備作業に膨大な時間をかけなければいけないって、冷静になって考えると「おかしい」ですよね。 いや、冷静にならなくてもわかるレベルでおかしい。 本当に必要なのは、文字起こしにかける時間を確保するのではなくて、文字起こしをしたうえで何を作るかを考える時間です。
これらの課題を今村さんたちが秒速で解決してくれました。今村さんたちが作ってくれた文字起こしアプリなら、音声や動画データを選択するだけで、勝手に文字を起こしてくれます。 文字起こしアプリによる文字起こしの精度は、人間が起こすレベルまでとは言わないものの、文字化されたテキストデータをもとに編集することを考えれば必要十分な内容です。 時間換算をするのであれば、1時間の取材に対して、従来は文字起こしに6時間、編集作業には6時間かかっていたのですが、 文字起こしアプリを使うことで、文字起こしの時間が30分程度まで短縮され、編集作業を込みでも6時間ほどで記事が完成できるようになりました。 しかも、文字起こしアプリが文字を起こしている間の時間は、別の作業ができるというのもうれしいポイント。
Ledge.aiが急成長を遂げた背景にも、この文字起こしアプリによる作業時間の短縮が間違いなくあります。編集部側の要望にも即座に応えてくれるため、使い勝手はバツグン。 文字起こしアプリによって、いろんな記事を作りやすくなりました。 改めて振り返ると、潜在的な課題をAIで解決するという綺麗な事例だと思います。恵まれているな……俺たち……。』
こんなにもエモーショナルに書いてもらいました。ベタ褒めいただき大変恐縮です。。
業務改善アプリケーションとして、今回の自動文字起こしツールは成功できたと思います。
特に、文字起こしに6時間かかっていたのが30分程度まで短縮でき、作業工数の大幅な削減が実現できました。
とはいえ、まだまだ改善すべき点が多々ある荒削りなツールなので、この評価で満足せず、社員の声を聞きながらアップデートを繰り返していきます。
最後に
今回はAzure Cognitive ServiceのAPIを用いた音声による自動文字起こしアプリケーション開発の紹介を行いました。
Azure Cognitive Serviceを使用することで、音声やテキストなどの業務改善に関する高度なAI技術を簡単に実装することができます。 特に、自前のツールにAI技術を組み込む場合は最適解になると感じました。
しかし、パッケージされて便利な分、モデルの再学習はやや大変です。 学習する仕組みは整っているものの、音声データと人間によるアノテーションが必要であるため、学習データの準備に工数がかかってしまいます。 今回使用したAzureのSpeech APIにおけるモデル学習の手順は こちら にまとめられています。
レッジでは今回のように、クライアント業務の課題感に対してAIなどの適切な技術で業務プロセスを改善していくための議論が日々行われております。もちろん議論や提案だけでなく、実際に手を動かし実装しながらクライアントの課題に向き合っています。
AIのトレンドを追うレッジだからこそ、AIでできることを業務改善などといった様々な形で実現し、そこで得られた経験を積極的に発信していきたいと思います。