こんにちは。初めまして。レッジのインターン生の大見川です。 レッジでは、 データサイエンス部門に所属していますが、 Ledge.ai でも記事を書いているので良ければご覧ください。 今回の記事では、「Pythonで機械学習の実装をしてみたい!」という方に向けて、初学者の1冊目におすすめな本を紹介します。 Pythonの勉強を始める前はプログラミングの経験は全くなく、HTMLもわからないようなレベルでした。そのような私でもこの本をベースに勉強を進めていくことで、ある程度コードが書けるようになったのできっと初学者のみなさんにとっても参考になると思います。
1冊目におすすめの本
私が最初に勉強していた本は「Pythonで動かして学ぶ!深層学習の教科書」です。正直、図書館で見つけて「これならわかりやすそうだし面白そうだなー」くらいの感覚で選びましたが、今考えても1冊目にはおすすめです。ここで注意してほしいことは、その本で「最終的に何をできるようになる本なのか」を確認して、自分が面白そうだと思う本を選んだ方がいいということです。なぜなら、プログラミングを勉強する上で(特に独学だと)一番大事なのは根気よく続けることだからです。この本は最終的に画像認識ができるようになることが目標ですが、他にも自然言語処理やデータ分析などPythonで出来る事はたくさんあります。その中で1番面白そうだと思うテーマを扱っている教材を選んだほうがいいと思います。
全体的な流れ
この本の大まかな流れは以下になります。
ここからはこの順番にそって説明していきます。
環境構築
プログラミングの勉強をする時に、まず環境構築をする必要があります。この本ではAnacondaというパッケージが紹介されています。これを使うと必要なライブラリが簡単にインストールできるようになり便利です。Anacondaのインストールから仮想環境の構築まで丁寧に説明されているので、説明されている通りに環境構築をしていきましょう。
機械学習の説明
次は「そもそも機械学習とは何か?」という説明から、よく使われる手法などの説明が書かれています。コードを書くことはありませんが、機械学習までの流れや、精度を上げるための技術など実装するときにも必要となる知識なので、しっかり読んで理解していきましょう。この記事では実際に実装するところで詳しく書きます。
Pythonの文法
いよいよ実際にPythonのコードを書いていきます。 まずはPythonの基礎ということで変数、型、if文の説明となります。本書ではそれぞれの項目が説明された後や、章の最後に問題が書かれているので、解いてみてください。読んで理解しても実際に手を動かすと分からないところが出てくると思うので、その度に説明部分を読み返すことが大事だと思います。
次はリスト型、辞書型、while文、for文の説明です。本に書かれている内容を少しずつ変えてどのように出力されるかを予想してみたり、問題の設定を変えて解いてみたりすると、より理解が深まると思います。
文法の最後は関数です。この章ではPythonにもともと組み込まれている関数やメソッドから、自分で関数を定義するところまで学びます。ここで注意してほしいことは、すべてを覚える必要はないということです。例えば、[1,3,5,2,4]というリストにsortというメソッドを用いると[1,2,3,4,5]というように並び替えることができますが、ここでは「なんか並び替えるメソッドあったなー」くらいの記憶で十分です。メソッドや組み込み関数は本で紹介されていないものもたくさんあり、全てを覚えていたらきりがないです。今回の例で言えば「Python 並び替え」のように調べれば色々な記事が出てくるので、検索してみましょう。実際に業務をする上でも忘れてしまったら、その度に調べれば良いので、どんどん進めていきましょう。
有名なライブラリの紹介
ここではPythonでよく用いられるライブラリを紹介していきます。ライブラリとは外部から読み込むPythonのコードの塊です。わかりにくいと思うので以下の図をご覧ください。今回はベクトル・行列の計算に特化したライブラリであるNumPyを表しています。

NumPyのrandomというモジュールの中randintという関数があるという感じです。この本ではNumPy、Pandas、matplotlibについて説明されています。
※ここから先は高校〜大学1年程度の数学の知識が必要な場面が出てきます。私は理系なのでそこで困ることはなかったのですが、「プログラミング以前に数学的にわからない」という状況になったら数学の勉強もするしかないです。「高校~大学1年程度の数学」といっても、その範囲の数学が完璧である必要は全くないので、プログラミングの勉強をしながら知らない話が出てきたら調べて勉強する程度で大丈夫です。
NumPy
Numpyの章では主にndarray配列を使って計算をしていきます。このあたりから少しづつ複雑になり、エラーが出てしまうこともあると思います。エラーが出たらそのエラー文をそのままコピペして検索してみましょう。多くのエラーは過去に同じ体験をした人が解決方法を書いてくれています。先ほどから「分からなかったり、忘れてしまったら検索」といっていますが、欲しい「情報を検索できる」というのも重要な能力です。 NumPyは画像処理だけでなくPythonを使う開発であれば、大体使われると思うので、何をやっているのかはしっかり理解していきましょう。
Pandas
この章ではPandasについての説明がされています。Pandasとは一般的なデータベースにて行われる操作が実行でき、数値以外にも氏名や住所といった文字列データも簡単に扱うことができるライブラリです。なのでデータ分析をする際には欠かせないライブラリとなります。
matplotlib
この章ではデータの可視化をすることができるmatplotlibというライブラリの説明がされています。データ分析をする上で可視化することは非常に有効な手段の1つであるので、こちらもデータ分析には欠かすことのできないライブラリとなります。
機械学習とは
ここまでで基礎的な知識は揃ったので、ようやく機械学習の実装に入っていきます。機械学習といっても大きく以下の3種類に分けることができます。
蓄積されたデータを元に新しいデータや未来のデータ予測、あるいは分類を行う。株価予測や画像認識が当てはまる。
蓄積されたデータの構造や関係性を見出すことを意味する。 小売店の顧客の傾向分析などで用いられる。
報酬や環境などを設定することで学習時に収益の最大化を図るような行動を学習する。 囲碁などの対戦型AIで用いられることが多い。
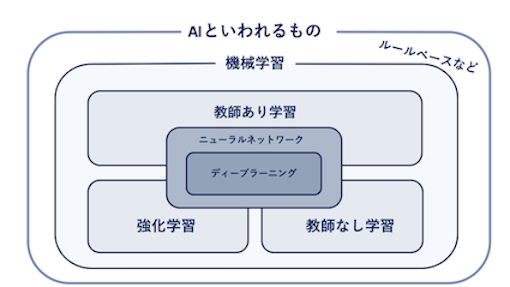
(引用元:機械学習をどこよりもわかりやすく解説! 教師ありなし学習・強化学習だけでなく5つのアルゴリズムも完全理解! )
ここでは画像認識を学ぶので、教師あり学習にあたります。 また、機械学習を実装する流れは以下のようになります。
2のデータクレンジングとは、データをモデルが学習しやすい形に加工する作業です。本書ではモデルを作成し、学習させるところをメインに扱っていますが、実際には重要な部分なのでしっかり理解してください。
また、深層学習というのは機械学習の手法の1つであり、上で述べた3のモデルを作るという場面で登場します。この本では、まず、深層学習ではないモデルで上の流れを1通り紹介して、最後にCNNという画像処理によく使われる深層学習を紹介されています。
機械学習の実装
この章ではまず、教師学習で用いられる機械学習のモデルが数種類紹介されています。具体的にはロジスティック回帰、SVM、決定木、ランダムフォレスト、k-NN等が紹介されています。これらのモデルはそれぞれ特有のハイパーパラメータを持っているので、それらの調整(チューニング)をするところまで学ぶことができます。
深層学習の実装
ここではMNISTという手書き文字のデータセットを用いて、簡単な深層学習の実装をします。この章を最後まで読み終えると、手書き数字画像データから数字を判別できるコードを書けるようになります。具体的にはディープニューラルネットワーク(DNN)という、層が何層にも重なったモデルを作り、DNNのハイパーパラメータをチューニングします。この流れはこれまでのDNN以外の機械学習の流れと同じです。
 (引用元:初心者のための畳み込みニューラルネットワーク(MNISTデータセット + Kerasを使ってCNNを構築) )
(引用元:初心者のための畳み込みニューラルネットワーク(MNISTデータセット + Kerasを使ってCNNを構築) )
CNNの実装
ついに最後の、画像認識でよく用いられるCNNを実装する章です。画像認識とは、画像や映像に映る文字や顔などいった「モノ」や「特徴」を検出する技術です。具体的には、画像の分類やモノの位置の推定など様々な認識技術が挙げられます。CNNとは畳み込みニューラルネットワークのことでConvolutional Neural Networkの略となります。
CNNは畳み込み層とプーリング層と呼ばれる層をいくつも重ねていくことで形成されます。 畳み込み層では、入力データの一部分に注目してその部分画像の特徴を調べます。例えば顔認識をする場合は、適切に学習が進むと、入力層に近い畳み込み層では線や点といった低次元な概念の特徴に、出力層に近い層では目や鼻といった高次元な概念の特徴に注目するようになります。 プーリング層は畳み込み層の出力を縮約しデータの量を削減する層と言えます。畳み込み層での畳み込みを行うと、同じような特徴が近くにあったり、うまく特徴を見つけることができない場所が出てきたりして、畳み込み層からの出力には無駄があります。プーリング層ではそのようなデータの無駄を削減し、情報の損失を押さえながらデータを圧縮します。一方、細かい位置情報などは失われてしまいますが、逆にこれで元の画像の平行移動などの影響を受けにくくなります。例えば、手書き文字認識を行う場合、数字の位置情報はあまり重要ではないのでそれを削除し、位置の変化に強いモデルとなります。
これらの層はKerasとTensorFlowというライブラリを使うと簡単に実装することができます。ここでは先ほども登場したMNISTに加え、10種類のカラー画像のデータセットであるCIFAR10を使って、CNNの実装をしていきます。
 (引用元:[ 人工知能に関する断創録 ] )
(引用元:[ 人工知能に関する断創録 ] )
データの水増し・転移学習
画像認識では、画像データとそのラベルの組み合わせが大量に必要になります。しかし、モデルを学習させるのに十分な量のデータセットを揃えることができないことは多々あります。そこで、画像の水増しというテクニックを使って、持っているデータの量を増やすことができます。具体的には、画像を反転・ずらし・色を変えるなどして、新たなデータを作ります。 この作業もKerasのImageDataGeneratorを使うと簡単に実装することができます。ImageDataGeneratorには多くの引数が存在し、それらの値を調節することで、画像を水増しすることができます。引数についての詳しい説明はこちら。
 (引用元:[ Wild Data Chase -データを巡る冒険- ] )
(引用元:[ Wild Data Chase -データを巡る冒険- ] )
また、大規模なニューラルネットワークを学習させるには、膨大なデータと時間が必要となります。そこで、「大量のデータですでに学習され公開されているモデルを使って新たなモデルを作ろう」というものが転移学習です。KerasではImageNetで学習済みの画像分類モデルとその重みをダウンロードして、使用します。公開されているモデルは数種類ありますが、ここではVGG16というモデルを使います。VGG16は1000クラスの分類モデルなので、出力ユニットは1000個ありますが、最後の全結合層は使わずに途中までの層を特徴抽出のために使用することで転移学習に用いることができます。
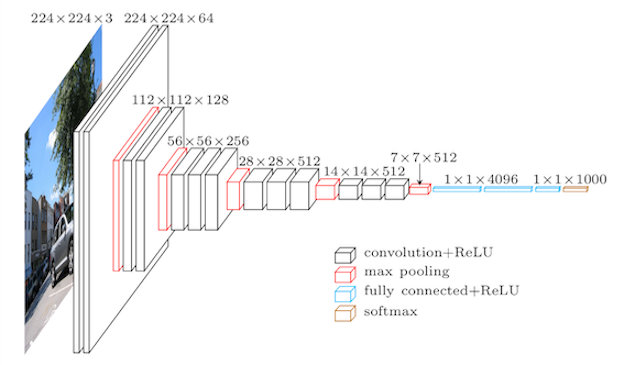 (引用元:[ 初心者のためのAI人工知能テクノロジーブログ ] )
(引用元:[ 初心者のためのAI人工知能テクノロジーブログ ] )
最後に
今回は、どういう風に勉強したかも交えながら、初めて読んだ本の内容を紹介してみました。前半は基礎的な話でPythonを使う際には必ず必要になる知識だと思います。後半部分は画像認識の話でしたが、ぜひ、これらの技術を使って何かアプリを作ったりしてアウトプットしてみてください。 また、他にも自然言語処理や時系列データの分析などPythonできることはたくさんあるのでそれらを学んでみるのもいいと思います。
書籍情報
「Pythonで動かして学ぶ! あたらしい深層学習の教科書 機械学習の基本から深層学習まで」
著者:株式会社アイデミー 石川 聡彦.
発売日:2018年10月22日.
出版社:翔泳社.
価格:3,200円 (税抜).