こんにちは。初めまして。レッジのユンです。レッジでは、データ・ドリブンなビジネス上の意思決定を導くため、データウェアハウス(DWH)作成やデータマート作成など、主にデータを整備する業務に取り組んでいます。
今回の記事では、私が最近読んだ「ビッグデータを支える技術」について書いていきます。
ちなみに、本書は直属の先輩から紹介していただきました。先輩は自分の業務だけではなく、データパイプラインの全般的な業務を理解することで、自分の業務にもっと興味を持って欲しいため、この本を紹介してくださったと思います。私が取り組んでいる業務にも関わっている内容の本なので、業務理解を深める機会になると思い、読みました。
「ビッグデータを支える技術」の内容
データパイプラインを構築するための基礎知識について紹介
データパイプラインとはデータの収集から蓄積、ストリーム・バッチ処理、分散処理、ワークフローまで次々と受け渡されるデータによって構成されるシステムのことです。
データを分析可能な状態にするためには、正しくデータを収集する必要があります。 この本はデータパイプラインを構築するために知っておくべき単語やツールを初心者でも理解できるように書いてあります。
パイプライン構築の各段階ごとに扱っているツールや使う時の注意点などの説明
特にこの本はデータパイプラインを説明しているだけではなく、パイプラインを構築しながら注意するべき内容も記載されています。例えば「ストリーム型のデータを転送する際にはイベント時間とプロセス時間の違いがあるので注意すること。解決法は~~」と説明されているので、実業務でも役立つと思います。
読んで何を学んだのか
ストリーミング型のデータ転送の仕組みを詳しく理解できるようになりました。
データ転送の仕組みは2種類ある
データを転送する仕組みは 「バルク型」 と 「ストリーム型」 があり、データ転送の仕組みによって扱う技術もサービスも違います。
バルク型
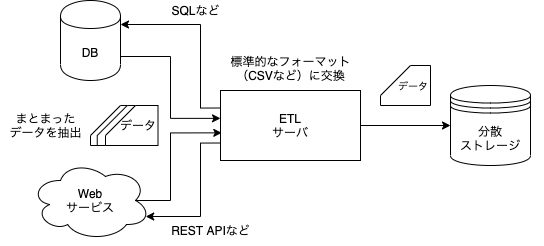
バルク型は大量のデータが既に存在している場合、既存のDBのデータを抽出したい場合によく用いられる転送方法です。既存の分散ストレージがない場合、ETLサーバを設置してフォーマットを合わせた後、分散ストレージにデータを転送します。
まとまったデータを転送する仕組みなので、ストリーミング型より高負荷に対応できるサーバは求められていません。また、ネットワーク通信による欠損が発生しても、データの転送をやり直せるのがバルク型の特長になります。
ストリーミング型
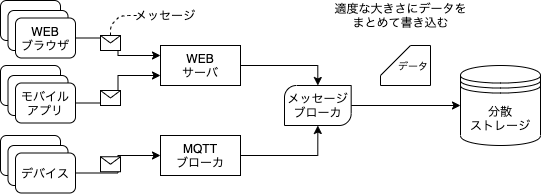
リアルタイムで生成されたデータを転送するため使われているのがストリーミング型です。
送受信されるメッセージ量と比較して、サーバから処理できる送信量より受信量のほうが多くなると、サーバの負荷が大きくなります。この問題を克服するためにも、短い時間に大量の送受信処理できるサーバが求められます。
モバイル回線のような信頼性の低いネットワークでは、メッセージが欠損している場合もあります。欠損データを考慮した設計を求められます。
リアルタイムにデータを送受信したり、データの欠損を防ぐためにストリーミング型のデータ処理を工夫
ストリーミング型は短時間に沢山の送受信処理を行う必要があります。そして、データの欠損がないように設計方式を検討する必要もあります。
サーバの負荷を減らすため、メッセージブローカを導入
ストリーミング型はリアルタイムでデータを転送しています。転送量が急に増えると、ディスクの読み書き性能が限界に達する可能性が高くなります。ディスクの性能が限界に達すると、エラーが発生し、最悪の場合、データの転送自体が中断される恐れがあります。
この問題を克服するために、サーバから分散ストレージの間には「メッセージブローカ」を設置します。「メッセージブローカ」は一時的にデータを蓄積し、データ量が一定レベルに到達すると、分散ストレージに転送します。その結果、ディスクの作業負荷を軽減させることができます。
データの欠損問題を解決するため、「at least once」の設計方式を導入
モバイル回線のような信頼性の低いネットワークからデータを転送すると、データの漏れや重複が発生しやすいです。それを解決するために、ほとんどの企業では「at least once」の設計方式を導入しています。
「at least once」設計方式はデータが重複して転送されることを認めることで、一回以上は各データが転送される設計方式です。データの重複を許すことで、データの欠損を減らせるのが特長になります。もちろん、重複データは後で排除できます。
ストリーミング型のデータを分析する時の基準は「イベント時間」
ストリーミング型でデータを収集するとしても、今日作られたデータが2日、3日後に収集されるケースがあります。電波が通じない環境にあるデバイス・電源が切れたデバイスはネットワーク環境に再度つながるまでにはデータの転送・収集ができないためです。 この時に「イベント時間」と「プロセス時間」の違いを明確に理解する必要があります。
- 「イベント時間」:メッセージが生成された時間
- 「プロセス時間」:メッセージがサーバに届いた時間
顧客のアクションを分析するにはイベント時間を使う必要があります。プロセス時間を使って分析すると、目的に沿わない分析になってしまいます。プロセス時間はメッセージがサーバに届いた時間ですので、分析の基準自体が変わります。
まとめると、過去のデータがまだ収集できなかったことも想定した上で分析すること、顧客のアクションを分析を行う時には、「イベント時間」を基準で分析すること、この2点を意識する必要があります。
感想
本書を読むことで、自分が携わっていないデータパイプラインの理解が深まりました。
私の業務はすでに作られている基幹システムのデータからDWHやデータマートを作成することです。そのため、基幹システムのデータが更新される仕組みを考慮せずとも業務を遂行できていました。しかし、今回本書を読むことで、基幹システムがデータを更新するために複雑な仕組みを持っていることが分かりました。
まだ業務で携わったことがないストリーム型のデータ処理に興味を持ちました。リアルタイムのデータをちゃんと分散ストレージまで転送することができれば、データパイプラインを扱うスキルも上がるので、すごく楽しいと思います。
書籍情報
 |
|